Questo articolo spiega i concetti principali della programmazione basata sui thread in Perl. Con le recenti versioni dell’interprete essi sono diventati infatti un’eccellete alternativa al forking.
L’articolo era stato originariamente concepito per la pubblicazione su una rivista cartacea italiana su Perl che avrebbe dovuto nascere ad inizio anni 2000, evento che poi non si è più verificato.
Nota Maggio 2018: benché ora esistano modi migliori per gestire la programmazione concorrente in Perl, questo articolo costituisce un’utile tutorial sull’argomento, e quindi rimane pubblicato.
Buona lettura!
Introduzione
È spesso di fondamentale importanza poter scrivere programmi nei quali viene compiuta più di un’operazione contemporaneamente. Ad esempio, in un programma che usa una GUI, è essenziale che l’interfaccia continui ad aggiornarsi e a rispondere all’utente anche mentre il programma sta compiendo altre operazioni. In altro ambito, la possibilità di gestire operazioni concorrenti. è utile per scrivere ad esempio dei daemon: un programma rimane in attesa di un evento e, quando questo si verifica, compie una serie di compiti rimanendo allo stesso tempo in attesa di un altro evento. In realtà, la contemporaneità vera e propria è possibile solo su architetture multiprocessore; su quelle a processore unico si ha comunque una percezione di esecuzione simultanea di più operazioni, poiché il tempo dell’unico microprocessore viene ripartito in maniera più o meno uguale tra le singole operazioni attive. Perl mette a disposizione dello sviluppatore due tipi di programmazione concorrente: quella basata sui processi, e quella basata sui thread. Il primo tipo prevede l’esistenza di un processo diverso per ogni operazione che si deve compiere in maniera concorrente, mentre il secondo prevede un unico processo che gestisce dei sottoprocessi denominati thread. La programmazione concorrente basata sui processi esiste sino dagli albori dei sistemi operativi Unix, e Perl è ottimizzato per renderla estremamente efficiente. Purtroppo, ciò è valido appunto nei sistemi Unix, ma non nella maggior parte degli altri (ad esempio Windows), in cui tale modello non è supportato. Esso è comunque emulato, utilizzando proprio i thread, ma a questo punto non è possibile azzardare previsioni per quanto riguarda l’efficienza. La programmazione concorrente basata sui thread è invece più recente, e tutti i sistemi operativi moderni, incluso Unix, forniscono un supporto oramai piuttosto stabile ad essa. Presentando quest’ultimo modello alcuni vantaggi su quello basato sui processi, esso è consigliabile nella maggior parte dei casi. Questo articolo si occuperà esclusivamente dei thread, e la programmazione concorrente basata sui processi non verrà trattata.
In Perl, i thread sono apparsi con la versione 5.005 dell’interprete, e la loro implementazione è stata poi completamente riscritta nella successiva versione 5.6; infine, essi hanno raggiunto una certa stabilità e l’interfaccia è divenuta completa con la versione 5.8. Il modello di thread che verrà trattato in questa sede è quello disponibile a partite dalla versione 5.6 di Perl, che si basa sui thread dell’interprete, i cosiddetti ithread. Il precedente modello è da considerarsi sorpassato, ed il suo uso è quindi sconsigliato. Al fine di poter usare i thread, è indispensabile che il vostro interprete Perl sia compilato con l’apposito supporto. Più o meno tutte le distribuzioni binarie di Perl 5.8 per ambienti Unix contengono il supporto per gli ithread, ed anche le recenti distribuzioni per Windows di ActiveState ne sono provviste. Per assicurarvi che il vostro interprete supporti gli ithread, lanciate il comando perl -V e controllate che da qualche parte nell’output sia presente la scritta useithreads=define. Se non c’è, siete condannati: dovrete procurarvi un’altra distribuzione dell’interprete, oppure ricompilarlo voi stessi con il supporto per gli ithread.
Concetti di base sui thread
Poniamo di gestire un pub “all’irlandese”, in cui un certo numero di avventori si presentano ad ordinare una o più birre per portarle poi al tavolo e berle con gli amici. Da bravi manager, abbiamo assunto cinque camerieri che si occupano di spillare da altrettante spine le birre che gli vengono richieste, e possiamo dunque gestire fino a cinque clienti contemporaneamente. Ogni cameriere, che lavora per i fatti suoi spillando le birre, può, a livello informatico, essere definito un thread: esso compie il suo lavoro contemporaneamente agli altri, rimanendo all’interno di un’unica entità che è il pub in cui lavora (il quale, continuando il parallelismo tra ristorazione ed informatica, è il processo). Di seguito è riportata una spiegazione grafica di tutto ciò:
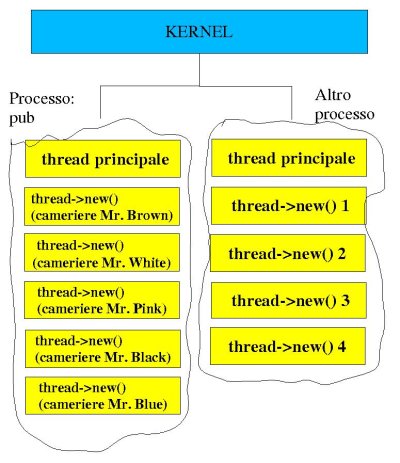
In Perl tutto questo è gestibile in maniera piuttosto semplice. Si osservi a tal proposito il seguente listato:
#!/usr/bin/perl
#
# Listato 1: Esempio di gestione delle ordinazioni di un pub
# utilizzando i thread di Perl
use strict;
use threads;
# Ora di chiusura del pub (ora attuale + un certo numero di secondi)
my $chiusura = time + 120;
# I camerieri... di Quentin Tarantino
my @camerieri = ('Mr. Brown', 'Mr. White', 'Mr. Pink', 'Mr. Black', 'Mr. Blue');
# Creazione dei thread
my @thr;
for (@camerieri) {
push @thr, threads->new(\&cameriere, $_);
}
# Unione dei thread
for (@thr) {
$_->join();
}
# Funzione principale di ogni thread/cameriere
sub cameriere {
my ($nome) = @_;
while (time < $chiusura) {
my $birre = int(rand(10))+1;
print "Cameriere $nome: sto servendo $birre birre\n";
sleep $birre;
}
}Il modulo da includere è threads. Per creare un thread è sufficiente invocare il metodo new() del modulo importato, secondo il seguente schema:
my $thr = threads->new(\&subroutine, $parametro1, $parametro2);new() richiede come primo argomento la subroutine che costituirà il corpo principale del thread,e poi accetta eventuali parametri che verranno passati a tale subroutine. In seguito alla chiamata a new(), l’esecuzione del nuovo thread inizia subito, a partire dalla subroutine indicata. Tutti i dati del programma (variabili e codice) vengono copiati, cosicché il thread abbia accesso ad essi. È importante notare che tutti i dati vengono duplicati, e non condivisi: le variabili del thread dunque non coincidono con quelle programma che lo ha generato, e modificare il valore di una all’interno di un thread non comporterà alcuna variazione nel thread principale o negli altri da voi creati. I valori iniziali di tutte le variabili sono quelli che esse avevano al momento della creazione del thread. Ciascun thread, dunque, si comporta come un programma sè stante, poiché nessun dato viene condiviso. Chiaramente è possibile, se lo si desidera, condividere esplicitamente alcuni dati, come vedremo in seguito. Sotto questo aspetto, il modello di Perl 5.6 è diverso da quello proposto dagli altri linguaggi, ed anche da quello di Perl 5.005: nella maggior parte delle implementazioni, infatti, i dati vengono normalmente condivisi, e non normalmente duplicati.
Nel nostro esempio, dopo la chiamata a new(), il programma principale continua la sua esecuzione normalmente, mentre nel nuovo thread creato l’esecuzione parte dalla subroutine cameriere(). Tornando al programma principale, il ciclo for continua fino a quando vengono creati cinque thread, uno per ogni cameriere, gli handle dei quali vengono memorizzati nell’array @thr. Appena viene creato, ogni thread entra in un ciclo while della durata di un certo numero di secondi (determinato dal valore della variabile $chiusura), in cui viene scelto a caso un numero tra 1 e 10, che rappresenta il numero di birre che il cliente ordina: il thread/cameriere visualizza un messaggio prima di servire il cliente, attende un numero di secondi pari al numero casuale creato, per simulare il tempo di spillamento, e poi si occupa di un nuovo cliente (nuova iterazione del while). Ecco un esempio dell’output del programma:
Cameriere Mr. Brown: sto servendo 3 birre
Cameriere Mr. White: sto servendo 10 birre
Cameriere Mr. Pink: sto servendo 9 birre
Cameriere Mr. Black: sto servendo 2 birre
Cameriere Mr. Blue: sto servendo 2 birre
Cameriere Mr. Black: sto servendo 3 birre
Cameriere Mr. Blue: sto servendo 3 birre
Cameriere Mr. Brown: sto servendo 9 birreIl sistema operativo commuta continuamente l’esecuzione dei vari thread, fornendogli un certo tempo della CPU a testa: in questo modo, mentre uno dei thread attende il ritorno da sleep(), gli altri continuano la loro esecuzione. Una volta raggiunta “l’ora di chiusura”, il ciclo while esce, ed il thread termina la sua esecuzione. Il controllo ritorna al programma principale, che nel frattempo si era posto in attesa della fine dell’esecuzione suoi thread da esso creati: il secondo ciclo for contiene infatti la chiamata al metodo join() di ciascun thread. Ognuna di queste chiamate blocca il programma principale finché il thread per il quale è stata compiuta non termina la sua esecuzione; questo, correttamente, impedisce al programma di uscire fino a quando ci sono thread ancora attivi. Se non inserissimo nel nostro programma alcuna chiamata a join(), esso terminerebbe la sua esecuzione quasi subito riportando l’errore:
A thread exited while 6 other threads were still running.che indica che il thread principale è uscito mentre gli altri erano ancora attivi, e che di essi è stata dunque forzata la terminazione prima che portassero a termine le loro operazioni. Se lo si desidera, join() ritorna il valore della funzione associata al thread. In caso tale valore di ritorno non sia desiderato, è possibile utilizzare detach() al posto di join(): questo metodo non blocca il programma, ma semplicemente ignora il thread per il quale viene chiamato, lasciando che esso esegua le sue operazioni, e gettando via l’eventuale valore di ritorno. È comunque indispensabile che, al momento del termine del programma principale, tutti i thread abbiano completato la loro esecuzione, altrimenti verrà visualizzato l’errore di cui sopra, anche se si è utilizzato il metodo detach().
Gestione delle variabili condivise
Come anticipato, con gli ithread nessuna variabile viene condivisa tra un thread e l’altro, a meno che non si specifichi esplicitamente una volontà in tal senso. Nella maggior parte dei casi è desiderabile condividere dei dati, e quindi ora vedremo come può essere fatto ciò. Nel listato mostrato di seguito è riportata un versione modificata del software che simula il nostro pub, che prevede la possibilità di regalare 5 birre ogni 50 o più vendute: viene tenuto un conto delle birre totali vendute, ed al cliente che causa il superamento del limite di 50 ne vengono regalate 5, ed il conto viene azzerato.
#!/usr/bin/perl
#
# Listato 2: Gestione dell'accesso sincronizzato a varaibili
# condivise tra più thread, utilizzando lock()"
use strict;
use threads;
# Ora di chiusura del pub (ora attuale + un certo numero di secondi)
my $chiusura = time + 120;
# Birre vendute sinora
my $vendute : shared = 0;
# I camerieri... di Quentin Tarantino
my @camerieri = ('Mr. Brown', 'Mr. White', 'Mr. Pink', 'Mr. Black', 'Mr. Blue');
# Creazione dei thread
my @thr;
for (@camerieri) {
push @thr, threads->new(\&cameriere, $_);
}
# Unione dei thread
for (@thr) {
$_->join();
}
# Funzione principale di ogni thread/cameriere
sub cameriere {
my ($nome) = @_;
while (time() < $chiusura) {
my $birre = int(rand(10))+1;
my $omaggio = 0;
{
lock $vendute;
$vendute += $birre;
if ($vendute >= 50) {
$vendute = 0;
$omaggio = 5;
}
}
print "Cameriere $nome: sto servendo $birre birre (+$omaggio)\n";
threads->yield();
sleep $birre + $omaggio;
}
}La variabile che mantiene il conto delle birre vendute è così dichiarata:
my $vendute : shared = 0;Questa sintassi impone la condivisione della variabile: modificarne il suo valore in un thread significa rendere visibile questa modifica anche a tutti gli altri thread. Un problema non banale è gestire l’accesso sincronizzato a tale variabile, evitando delle race condition (circostanze in cui più di un thread accede allo stesso dato in maniera non sincronizzata). Ogni thread/cameriere infatti ne incrementa il valore del numero di birre ordinate, poi guarda se esso ha superato 50, ed in caso affermativo lo riporta a 0. Vediamo cosa potrebbe verificarsi se due camerieri accedessero simultaneamente a tale variabile:
$vendute = 44
Mr. Black: $vendute += 9 --> $vendute = 53
Mr. Black: siccome $vendute = 53, entra nell'if
Mr. White: siccome $vendute = 56, entra nell'if
Mr. White: azzera $vendute e regala 5 birre
Mr. Black: azzera $vendute e regala 5 birreLe birre vengono dunque regalate due volte: questo è solo un esempio di ciò che potrebbe accadere, poiché il sistema operativo può gestire in maniera molto diversa il modo in cui i thread Mr. Black e Mr. White si alternano. Una delle vie percorribili al fine di evitare inconvenienti come questo comporta l’utilizzo dela funzione lock(), come si vede nello stesso Listato 2. La chiamata a lock() su $vendute fa sì che venga controllato se qualche altro thread non abbia già compiuto una chiamata uguale sulla stessa variabile: in caso negativo, l’esecuzione del thread procede normalmente; in caso positivo, il thread blocca fino a che l’altro lock non viene rilasciato. In questo modo si garantisce che solo un thread alla volta possa compiere un certo numero di operazioni sulla variabile condivisa, prima che ad essa possano accedere altri. È molto importante tener conto del fatto che lock() non effettua alcuna operazione sulla variabile passata come parametro, e di fatto è possibile accedere ad essa sia in lettura che in scrittura anche se qualche altro thread ne detiene il lock; ciò che lock() impedisce è la possibilità di ottenere un lock su una variabile per cui ne è già stato rilasciato uno ad un altro thread. Da ciò deriva il fatto che è fondamentale che tutti i thread che usano una variabile condivisa chiamino la funzione lock() su di essa. La chiamata a lock() e le altre operazioni che agiscono su di essa sono incluse in un blocco di codice. Questo è necessario poiché non esiste alcuna funzione unlock(), ed il lock sparisce solo quando esce dallo scope: senza includerlo in un blocco anonimo, esso sarebbe uscito di scope alla fine del while, e ciò avrebbe comportato che nessun thread potesse accedere a $vendute anche durante la chiamata a sleep(), il che avrebbe causato un inutile momento di blocco. In questo secondo esempio abbiamo aggiunto una chiamata a yield() subito prima di quella a sleep(): essa non è indispensabile, ma ha la graziosa funzione di suggerire al sistema operativo di passare il controllo ad un altro thread prima che esso decida da solo di farlo. Può risultare utile per ottimizzare al massimo i tempi della CPU.
Esiste un’altra soluzione, più complessa, che prevede l’uso dei semafori. Si tratta fondamentalmente di contatori che, nei casi più semplici, si comportano in maniera simile ai lock. Un semaforo è un oggetto, che può essere inizializzato come segue:
use Thread::Semaphore;
my $semaforo = new Thread::Semaphore;Un semaforo implementa due metodi: up() e down(). Il primo incrementa il contatore di una unità, mentre il secondo lo decrementa. Se il contatore ha valore 0, la chiamata a down() causerà il blocco finchè una chiamata a up() non ne incrementa nuovamente il contatore. Tenendo conto che, alla creazione di un semaforo, il valore iniziale assunto da contatore è 1 (a meno che non venga specificato diversamente passando un parametro a new(), il ciclo while all’interno di ogni thread può essere riscritto nel seguente modo:
while (time() < $chiusura) {
my $birre = int(rand(10))+1;
my $omaggio = 0;
$semaforo->down();
$vendute += $birre;
if ($vendute >= 50) {
$vendute = 0;
$omaggio = 5;
}
$semaforo->up();
yield();
print "Cameriere $nome: Sto servendo $birre birre (+$omaggio)\n";
sleep $birre + $omaggio;
}Con la chiamata a down() il contatore assume valore 0, ma il thread non si blocca e quindi vengono compiute le necessarie operazioni su $vendute. Durante questo tempo, ogni chiamata a down() da parte di altri thread rimane bloccata, poiché il contatore vale 0; non appena il primo thread chiama up(), il contatore torna a 1 ed uno degli altri thread può sbloccarsi. Come si intuirà, i semafori sono più versatili dei lock, e si prestano alla gestione di situazioni più complesse, che in questa sede non verranno tuttavia trattate.
Note sugli inconvenienti e sulle prestazioni dei thread
Uno dei più fastidiosi inconvenienti in cui ci si imbatte nell’uso dei thread è la chiamata alle librerie di sistema, che potrebbero non essere thread-safe (scritte cioè in modo da poter lavorare in maniera corretta con i thread). Funzioni quali gmtime() o rand() effettuano infatti delle chiamate a librerie del sistema operativo, sulle quali Perl non ha controllo. Dovrete quindi documentarvi sul supporto che le vostre librerie di sistema hanno nei confronti dei thread prima di affidarvi completamente ad esse.
Un’altra cosa da ricordare è che, benché tutti i dati siano separati tra un thread e l’altro, salvo condivisione esplicita, ci sono operazioni che un thread può compiere influenzando l’intero processo, e di conseguenza tutti gli altri thread. Un esempio è l’uso di chdir(): questa subroutine cambia la directory corrente, che è chiaramente condivisa dall’intero processo.
A livello di prestazioni, i thread dipendono molto dal sistema operativo e da come esso li gestisce. Senza dilungarci su questioni che non riguardano Perl come linguaggio, ci limiteremo ad un’osservazione sull’efficienza degli ithread. Come scritto prima, alla creazione di ogni nuovo thread, viene effettuata una copia di tutti i dati (non condivisi) del programma: questa operazione porta via un certo tempo, ed una certa quantità di memoria. Quindi, se possibile, è bene creare i propri thread presto, prima che il programma dichiari troppe variabili o accumuli troppi dati; inoltre, il proprio programma dovrebbe essere studiato affinchè usi un numero di thread il più ridotto possibile: con ciò non si stà consigliando di creare meno thread a tutti i costi, ma di valutare bene quali servono ed a quali è invece possibile rinunciare. Conclusioni
In questo articolo abbiamo portato a termine un’introduzione all’uso dei thread in Perl. Dalla versione 5.8.0 essi hanno raggiunto un grado di maturazione che permette di considerarli come una valida alternativa a soluzioni quali fork() (programmazione concorrente basata sui processi). Tuttavia, i thread richiedono al programmatore di prestare un po’ di attenzione, soprattutto per quanto riguarda la sincronizzazione dell’accesso ai dati. Come si è visto, si possono creare alcune situazioni in cui potrebbe non essere così semplice capire dove si ha commesso un errore. In ogni caso, le ultime versioni di Perl mettono a disposizione tutto quanto è necessario per programmare con i thread in maniera sicura.